

誰がどうやって作ったのか?――ChatGPTの基礎知識⑥by岡嶋裕史
彗星のごとく現れ、良くも悪くも話題を独占しているChatGPT。新たな産業革命という人もいれば、政府当局が規制に乗り出すという報道もあります。いったい何がすごくて、何が危険なのか? 我々の生活を一変させる可能性を秘めているのか? ITのわかりやすい解説に定評のある岡嶋裕史さん(中央大学国際情報学部教授、政策総合文化研究所所長)にかみ砕いていただきます。ちょっと乗り遅れちゃったな、という方も、本連載でキャッチアップできるはず。お楽しみに!
過去の連載はこちら
岡嶋さんの好評既刊
ChatGPTはここから始めることができます
OpenAI
GPTシリーズはどのように作られたのだろう?
まず、作っているのはOpenAIである。名前からするととてもオープンな予感がする。実際非営利法人として登録されているが、OpenAI LPという子会社を持っていてこちらは営利組織である。
OpenAIを率いた面々も、サム・アルトマン、イーロン・マスク、ピーター・ティールと、一筋縄ではいかない人たちがそろっている。技術で世界を次のステージへ進めようと考えている面子だ。その「次のステージ」はもちろん「今よりいい世界」を目指しているが、誰にとっていい世界かはよく考えないといけないし、世界を変える大仕事のついでに巨額の利潤とヘゲモニーの拡大も達成するつもりだろう。少なくとも、匿名で全財産を寄附していくような慈善事業家たちではない。世界に爪痕を残すことを望んでいる。彼らのOpenAIにおけるミッションはAGI(汎用人工知能)の実現だ。
GPTはGenerative Pre-trained Transformerの略
OpenAIはDALL・E(画像生成AI)なども手がけているが、圧倒的に有名なのはGPTシリーズである。GPTはGenerative Pre-trained Transformerの略で、Generativeは生成のことである。ブームになった「生成系AI」の「生成」である。生成系AIブームは静止画から始まったが、OpenAIのGPTは自然言語(人間の言葉)を生成する。
Pre-trainedはちょっと説明が必要だろう。これは学習済み、訓練済みを表している。「AIを作りたい」と思ったときにアプローチ方法はいくつかあるが、まずはモデルを作る。汎用的なモデル(人間の代わりができるような)はまだない。だから、目的に応じて画像認識モデルや言語生成モデルを使い分けるのである。
自分でモデルを作るのが難しいな、めんどくさなと思ったら、誰かが作って公開しているモデルを借りてくるのでもいい。ただし、モデルは育てなければ意味がない。データを用意して学習させ、使い物になるように調整するのだ。
育てる難しさ
最近はデータさえ集められれば、育てる部分の手間は機械学習によって大幅に省くことができる。それでも全自動ではないし、育ったモデルだって、開発者の思い通りに育つとは限らないから「放送禁止用語はしゃべらない」「性別や人種、出身地によるバイアスを発生させない」といったチューニング(調整処理)が必要になる。何より、データを集め、選別するのが地獄みたいな難事業である。莫大な量がいるし、「正しい」データであることを確認しなければならない。
間違った教科書を作って子どもに与えたら、ろくでもない知識を吸収してしまうのと同じである。AIは与えられた知識をギャングエイジの子どもみたく、スポンジのように吸収するのだ。取りあえずWikipediaさえ与えておけばなんとかなるだろうとか、Twitterのデータで会話もばっちりなんて考えているとひどい目に遭う。
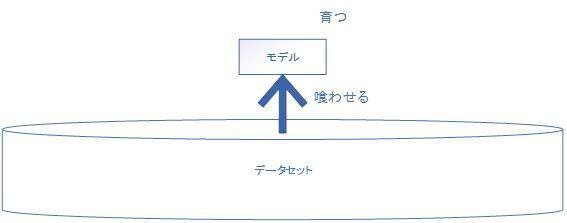
となると、多くの人にとってこのプロセスが障害になってしまう。大学の授業で、「ちょっと機械学習の練習をしてみようぜ」といって、データをほいほい用意できる学生はいない。
データセット
中にはデータセットを学習用や研究用に無償で公開してくれている優しい人や団体もある。MNISTなんて定番である。

手書きの数字をめっちゃ用意してくれていて、これは「1」こっちは「7」といったラベルまでつけてくれているので、すばやく教師あり学習などを実践することができる。
ただ、思うのだけれども、こういうデータ1つとっても「日本人の手書き数字じゃない」のである。これを元に学習したモデルは、日本で教育を受けた人が書いた数字の認識率が低くなるかもしれない。
数字くらいならたいしたことないと思われるかもしれないが、遺伝子の研究に使われているデータセットは大半が白人の遺伝子だと言われている。そこから導かれた遺伝子治療の知見が別の国、別の地域の人には有効でなかったり、思い通りの機序にならない可能性は存在する。現代においてモデルやデータで主導権を持つことがどれだけ重要かを物語るエピソードではある。
データセットは便利だが、すべての分野でこういうデータが整えられているわけではないし、秘中の秘にしている企業、組織もある。スクレイピングといってWebから自動的にデータを収集したりするのだが、誤っていたり、偏りがあったり、著作権的に問題があったりして使えないことも多い。
育成済み
Pre-trainedはもう育てちゃった後のモデルであることを示している。一番めんどうな「学習」をOpenAIがやってくれたわけである。GPTシリーズを多くの人が歓迎して、利用した理由の一つである。すぐ使えるのだ。
もちろん、育っちゃった後だと、自分で育てる楽しみや、思い通りに育てる柔軟性はないが、ほとんどの人にとってそれらはいらぬ苦労である。

自然言語処理向けのディープラーニングモデル
Transformerは自然言語処理向けのディープラーニングモデルで、長い言葉を並列に扱える特徴がある(文頭から文末へ順番に進んでいく必要がない)。だから、受け取った言葉を解析するのも、巨大なデータから学習するのも、短時間で終わらせられるようになった。今すごく人気のあるモデルで、OpenAIのGPTシリーズもGoogleのBERTもこれを利用している。
ところで、モデルというのはモデルでしかない。
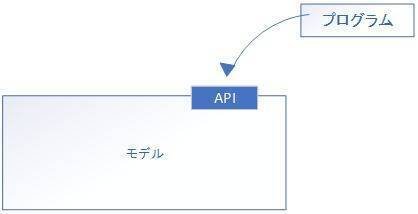
何かデータを入れれば、それを解析して反応し、出力を返してくるが、その「何か入れる部分」や「出てきた結果をどっかに表示する部分」は利用者が用意する必要があった。
こうしたモデルは「自分のために作る場合」と「人に使わせてあげることも想定する場合」があり、自分のためだけに作られたモデルだと内部構造を解析したり、そこに介入する方法まで考えないと外部からは操れない。とても手間がかかるし、そもそも外部から使うことを禁じていることも多い。
乱立する「○○GPT」「××GPT」
GPTシリーズは「人に使わせてあげることを想定」しているので、API(Application Programming Interface)という窓口がついていて、そこに「こんな風にして欲しい」とお願いすると、やはりAPIを通して結果が出てくるようになっている。外部のプログラム(アプリ)はAPIごしにGPTを使うのである。
だからいろんな人や企業がアプリを作ってGPTの力を借りている。最近、「○○GPT」とか「××GPT」という製品をよく見かけるが、あれは言語処理の部分はGPTに依存していて、それをもとに校正をしたり、書籍のタイトルを提示したり、料理のレシピを作ったりしているのである。
えっ、GPTのパクリなのか! と思われるかもしれないが、OpenAIが許している使い方である。また、GPTは汎用製品なので、特定用途ではこなれないことも多い。GPTを利用しつつ、アプリの部分で調整してあげると「校正用に使いやすくなった」「小学生向けの文章要約が上手になった」という製品にすることができる。
でも、さすがに乱立気味というか、あんまり××GPTが多すぎて、本家のOpenAIが作っていると誤解されるケースも目立った。そこでOpenAIは2023年4月24日に声明を出し、「××GPT」という名称を禁止した。今後はGPTを使っていることを示す場合は「×× powered by GPT」や「Powered by ××」と表記することになる。(続く)
岡嶋裕史(おかじまゆうし)
1972年東京都生まれ。中央大学大学院総合政策研究科博士後期課程修了。博士(総合政策)。富士総合研究所勤務、関東学院大学経済学部准教授・情報科学センター所長を経て、現在、中央大学国際情報学部教授、政策文化総合研究所所長。『ジオン軍の失敗』『ジオン軍の遺産』(以上、角川コミック・エース)、『ポスト・モバイル』(新潮新書)、『ハッカーの手口』(PHP新書)、『思考からの逃走』『実況! ビジネス力養成講義 プログラミング/システム』(以上、日本経済新聞出版)、『構造化するウェブ』『ブロックチェーン』『5G』(以上、講談社ブルーバックス)、『数式を使わないデータマイニング入門』『アップル、グーグル、マイクロソフト』『個人情報ダダ漏れです!』『プログラミング教育はいらない』『大学教授、発達障害の子を育てる』『メタバースとは何か』『Web3とは何か』(以上、光文社新書)など著書多数。